SOE 高频上报问题分析与优化报告
一、现象描述与初步分析
在 DAB 功率模块实验过程中,上位机通过 TCP Modbus 与控制器进行通信。控制器启动并运行一段时间后,上位机与控制器之间的 TCP 连接异常中断。随后通过串口登录控制器 Linux 系统进行检查,发现 Linux 侧所有应用程序均已退出,且未生成任何异常退出日志。
问题初期怀疑与程序启动方式有关。由于控制器软件曾通过 SSH 或串口终端远程启动,当调试笔记本与控制器断开连接后,登录 shell 可能被系统回收,进而导致其子进程被动退出。为排除该因素,后续将 Linux 侧启动方式修改为开机自启动,并增加异常退出诊断机制:一方面在应用程序崩溃后自动生成 CoreDump 文件;另一方面修改应用加载程序 hcploader,使其在启动成功后点亮主控板背后的绿色运行指示灯,并捕捉 SIGINT、SIGTERM、SIGQUIT、SIGABRT、SIGSEGV、SIGBUS、SIGILL、SIGFPE 等异常退出信号,在异常退出时点亮红色告警灯。
但在后续实验过程中,问题仍然复现。复现时系统未产生异常日志,未生成 CoreDump 文件,红色告警灯也未点亮。这说明应用程序并未通过上述可捕捉信号正常退出或崩溃退出。结合现象判断,进程存在被系统以不可捕捉信号终止的可能,其中重点怀疑 Linux OOM 机制触发后使用 SIGKILL 杀死进程,导致应用程序无法执行退出处理逻辑。
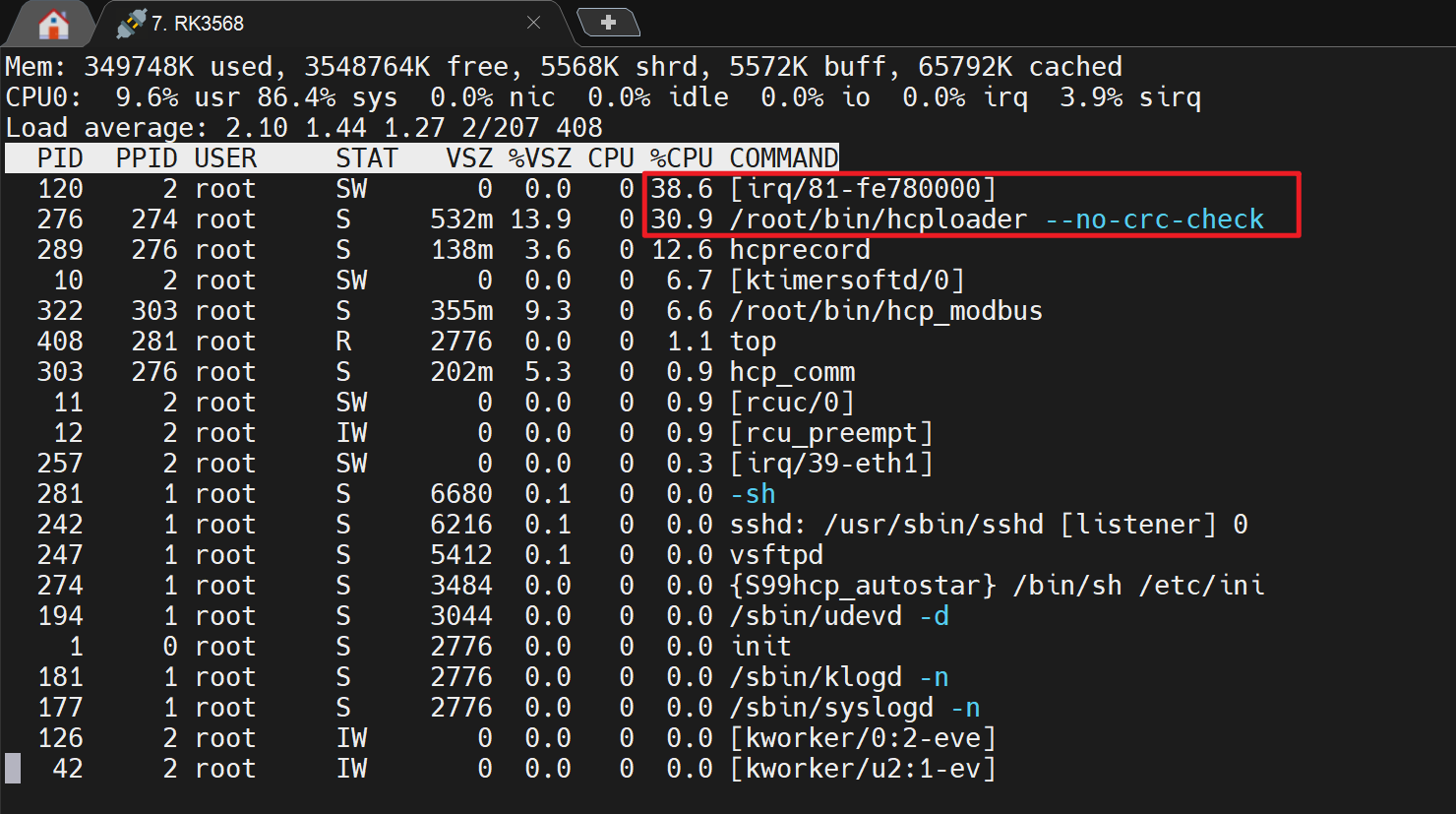
再次通过 SSH 登录控制器后,使用 top 命令查看系统资源占用情况,发现 hcploader 进程以及 [irq/81-fe780000] 内核线程的 CPU 和内存占用均异常偏高。进一步查阅 RK3568 硬件手册可知,fe780000 对应 mailbox 硬件模块;在 HCP 平台中,该 mailbox 中断用于 Linux 与裸核引擎之间的消息交互。
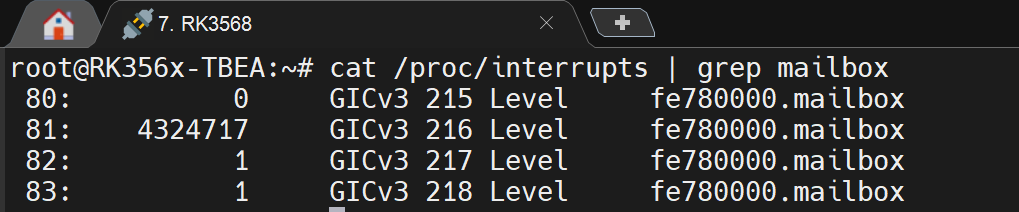
随后通过 cat /proc/interrupts 查看系统中断计数,发现 IRQ 216 的触发频率异常,中断计数约以每秒 20k 次的速度增长,该频率与控制周期基本一致。由此基本可以判断,裸核引擎侧 SOE 事件触发频率过高,导致 mailbox 中断持续高频上报,Linux 侧应用程序和中断处理线程来不及处理消息,最终形成消息拥塞和资源持续增长。当系统内存压力进一步增大后,hcploader 等应用进程可能被 Linux OOM 机制杀死,因此未能留下应用层异常日志、CoreDump 文件或红色异常灯状态。
综上,当前问题的直接表现为 Linux 侧应用程序异常消失;其可能原因并非普通程序崩溃,而是 SOE 高频触发导致 Linux 与裸核之间的消息通道拥塞,进一步引发系统资源耗尽,并最终触发 OOM 杀进程机制。
二、 SOE 实现机制的问题分析
结合 HCP 引擎侧 SOE 的实现机制分析,本次异常退出问题与 SOE 高频变位上报具有直接关联。
HCP 引擎中的 SOE 并不是由硬件中断直接触发,而是在每个 FB 任务周期末尾进行扫描。任务调度流程中,hcp_soe_scan() 位于 pre_task、run、post_task 之后执行:
static void hcp_task_handler(void)
{
uint64_t start_time, end_time, exec_time;
start_time = HAL_GetSysTimerCount();
if (HCP_LIKELY(hcp_fb_is_ready())) {
hcp_fb_pre_task();
hcp_fb_run();
hcp_fb_post_task();
hcp_soe_scan();
hcp_fault_scan();
}
...
}
这种设计可以保证 SOE 扫描时,输入已经更新、功能块逻辑已经执行完成、输出结果也已经写出。此时读取功能块成员变量,得到的是本周期最终稳定值,可以避免扫描到中间态数据。但这也意味着,SOE 的扫描频率基本等于 FB 任务周期。如果 FB 任务周期为 50 μs,则 SOE 扫描频率约为 20 kHz。
SOE 监测点注册后,引擎会保存被监测变量的内存地址以及上一次扫描值:
typedef struct {
uint8_t active;
uint8_t value_type;
uint8_t width;
uint8_t reserved;
volatile void *addr; /* 被监测变量地址 */
uint32_t current_raw; /* 上一次扫描值 */
} hcp_soe_entry_t;
每次执行 hcp_soe_scan() 时,引擎都会读取当前值,并与 current_raw 进行比较。如果值发生变化,则生成 SOE 通知并通过 rpmsg 信道发送给 Linux 侧:
void hcp_soe_scan(void)
{
hcp_soe_flush_pending();
for (i = 0; i < s_active_count; ++i) {
next_raw = hcp_soe_read_raw(entry->addr, entry->value_type);
if (next_raw == entry->current_raw) {
continue;
}
notify.engine_index = i;
notify.timer5_count = HAL_GetSysTimerCount();
notify.old_raw_u32 = entry->current_raw;
notify.new_raw_u32 = next_raw;
entry->current_raw = next_raw;
hcp_soe_send_notify(¬ify);
}
}
由此可见,只要某个 SOE 监测变量在相邻两个任务周期之间持续变化,就会在每个任务周期都触发一次 SOE 通知。例如,如果将周期计数器、实时采样值、中间计算量、调试变量或快速翻转的状态量注册为 SOE 监测点,就可能导致 SOE 事件以控制周期频率持续产生。
SOE 通知通过独立 rpmsg 信道发送,发送方式为非阻塞:
int hcp_soe_send_notify(const hcp_soe_notify_t *notify)
{
ret = rpmsg_lite_send(s_rpmsg,
s_soe_ept,
s_linux_soe_ept_addr,
(char *)notify,
sizeof(*notify),
RL_DONT_BLOCK);
return (ret == RL_SUCCESS) ? 0 : -1;
}
非阻塞发送可以避免 Linux 侧处理较慢时反向阻塞引擎实时任务,但该机制本身没有流控能力。也就是说,引擎只负责按照 SOE 变位产生速度持续发送通知,并不会等待 Linux 侧处理完成。当 SOE 触发频率过高时,Linux 侧会被大量 rpmsg 消息持续打断和唤醒。
本次实验中,通过 /proc/interrupts 观察到 IRQ 216 的中断计数约以每秒 20k 次增长,该频率与控制任务周期基本一致。而 [irq/81-fe780000] 对应 RK3568 mailbox 中断处理线程,在 HCP 平台中用于 Linux 与裸核引擎之间的 rpmsg 消息交互。因此可以判断,引擎侧很可能存在 SOE 监测点在每个 FB 周期都发生变位,导致 SOE 通知以约 20k/s 的频率持续上报,从而引起 mailbox 中断异常频繁触发。
Linux 侧 hcp_soe_service 接收到 SOE 通知后,还需要完成事件解析、时间戳校正、CSV 文件写入以及 NNG 消息发布等处理。当 SOE 事件以 20k/s 左右的速率持续输入时,Linux 侧处理能力可能不足,进而造成 CPU 占用升高、消息积压、文件写入压力增大以及内存占用持续增长。
因此,本次问题可以归纳为以下链路:
SOE 注册点包含高频变化变量
↓
每个 FB 任务周期都检测到变位
↓
引擎通过 rpmsg SOE 信道持续发送通知
↓
RK3568 mailbox 中断被高频触发
↓
IRQ 216 中断计数约 20k/s 增长
↓
Linux 侧 hcp_soe_service 处理不过来
↓
CPU 和内存占用异常升高
↓
系统触发 OOM,应用进程被 SIGKILL 杀死
由于 SIGKILL 无法被应用程序捕捉,进程在被 OOM 杀死前无法执行异常处理逻辑。因此,即使 hcploader 已经注册了异常信号处理函数,也不会生成应用层异常日志,不会生成普通崩溃路径下的 CoreDump 文件,红色异常灯也不会被点亮。
综上,本次现象更符合“SOE 高频变位上报导致 Linux 侧 rpmsg/mailbox 消息拥塞,最终引起资源耗尽并触发 OOM 杀进程”的故障链路,而不是普通程序崩溃或可捕捉异常退出。
三、修改方案:增加 SOE rpmsg 发送侧流控机制
针对 SOE 高频变位导致 Linux 侧 rpmsg/mailbox 消息拥塞的问题,本次修改在引擎侧 SOE 发送路径中增加流控机制。修改目标是在不影响 FB 实时任务执行的前提下,限制单位时间内实际发送到 Linux 侧的 SOE 通知数量,避免故障动作或异常变位风暴场景下,Linux 侧 hcp_soe_service 因持续处理高频 SOE 消息而出现 CPU 占满、内存增长、系统卡顿甚至 OOM 杀进程的问题。
原有 SOE 机制中,hcp_soe_scan() 在每个 FB 任务周期末尾执行。只要监测点发生变位,引擎就会立即通过 rpmsg SOE 信道向 Linux 侧发送 hcp_soe_notify_t 通知。该发送过程采用非阻塞方式,可以保证 Linux 侧处理较慢时不会反向阻塞引擎实时任务,但原机制缺少发送速率限制。当 SOE 监测点出现控制周期级变位时,Linux 侧可能在短时间内收到大量通知,最终造成消息处理拥塞。
本次修改采用基于 TIMER5 计数的秒级窗口限速方案。TIMER5 频率为 24 MHz,即 1 秒对应 24,000,000 个 tick。引擎侧通过当前 HAL_GetSysTimerCount() 计算当前所处的秒级窗口,并统计该窗口内已经成功发送的 SOE 通知数量。每个 CPU 核每秒最多允许实际发送 256 条 SOE 通知,超过该数量后,新的 SOE 变位通知将被主动丢弃并累计丢弃计数。
核心限速逻辑如下:
#define HCP_SOE_TICKS_PER_SEC PLL_INPUT_OSC_RATE
#define HCP_SOE_MAX_PER_SEC 256U
static uint64_t s_rate_window;
static uint32_t s_rate_sent;
static int hcp_soe_rate_check(void)
{
uint64_t now = HAL_GetSysTimerCount();
uint64_t window = now / HCP_SOE_TICKS_PER_SEC;
if (window != s_rate_window) {
s_rate_window = window;
s_rate_sent = 0U;
}
return (s_rate_sent < HCP_SOE_MAX_PER_SEC) ? 1 : 0;
}
流控逻辑加在真正调用 hcp_soe_send_notify() 之前。对于新检测到的 SOE 变位,如果当前秒级窗口仍有发送配额,则正常发送;只有发送成功后才累计 s_rate_sent。如果当前窗口配额已经用尽,则该条新变位通知直接丢弃,并累计背压丢弃计数。
entry->current_raw = next_raw; /* 本地状态先更新 */
if (!hcp_soe_rate_check()) {
s_backpressure_drop_count++;
continue;
}
if (hcp_soe_send_notify(¬ify) != 0) {
hcp_soe_enqueue(¬ify);
} else {
s_rate_sent++;
}
对于 pending 队列中的历史待发送通知,处理策略与新变位不同。pending 队列中的消息表示此前已经检测到变位并完成组包,只是由于 rpmsg 通道暂时不可发送而进入重试队列。因此,当本秒发送配额用尽时,pending 消息不会被丢弃,而是保留在队列中,等待下一秒窗口恢复后继续发送。
while (s_pending_count > 0U) {
if (!hcp_soe_rate_check()) {
return; /* 本秒配额用尽,保留 pending 队列 */
}
if (hcp_soe_send_notify(¬ify) != 0) {
return; /* rpmsg 仍发送失败,下周期继续重试 */
}
s_rate_sent++;
/* 发送成功后再出队 */
}
本次修改后,SOE 丢弃分为两类:一类是原有 pending 队列满导致的丢弃,表示 rpmsg 发送失败后重试缓冲区溢出;另一类是新增的流控丢弃,表示当前秒级窗口发送配额已经用尽,新产生的 SOE 变位被主动丢弃。新增流控丢弃计数通过 s_backpressure_drop_count 统计,并通过 GET_STATUS 接口上报为 soe_drop_count,最终由 debug adapter 转换为 JSON 字段 soeDropCount,并在上位机 Resource Explorer 中显示为 SOE: dropped N。这样现场人员可以直接观察当前是否发生 SOE 背压丢弃,从而判断系统是否仍存在高频 SOE 变位问题。
本方案的主要特点是:流控完全在引擎发送侧实现,不依赖 Linux 侧 ACK 或协议交互;使用已有 TIMER5 时间基准,与 SOE 通知时间戳体系一致;每核每秒 256 条的发送上限能够满足一般 SOE 事件记录需求,同时可以有效抑制控制周期级变位风暴;超限丢弃具备可观测性,便于现场定位和验证。
需要说明的是,该方案的目标是保护 Linux 侧系统资源,避免 SOE 高频上报拖垮 rpmsg、CSV 写入和 NNG 发布链路,并不保证 SOE 事件的完整可靠传输。当系统进入流控状态后,部分新变位事件会被主动丢弃,且由于 current_raw 已经更新,这些事件后续无法恢复。因此,后续仍需要从配置和应用层面避免将周期计数器、实时采样值、中间计算量、快速翻转状态量等控制周期级变化变量注册为 SOE 监测点。
综上,本次修改通过“秒级窗口限速 + 新变位主动丢弃 + pending 跨窗口保留重试 + 丢弃计数上报”的方式,在引擎侧为 SOE rpmsg 通道增加了基础背压保护能力。该机制可以有效降低 SOE 变位风暴对 Linux 侧的冲击,避免因 mailbox 中断和用户态 SOE 处理链路长期过载而引发系统资源耗尽
四、修改后验证结果
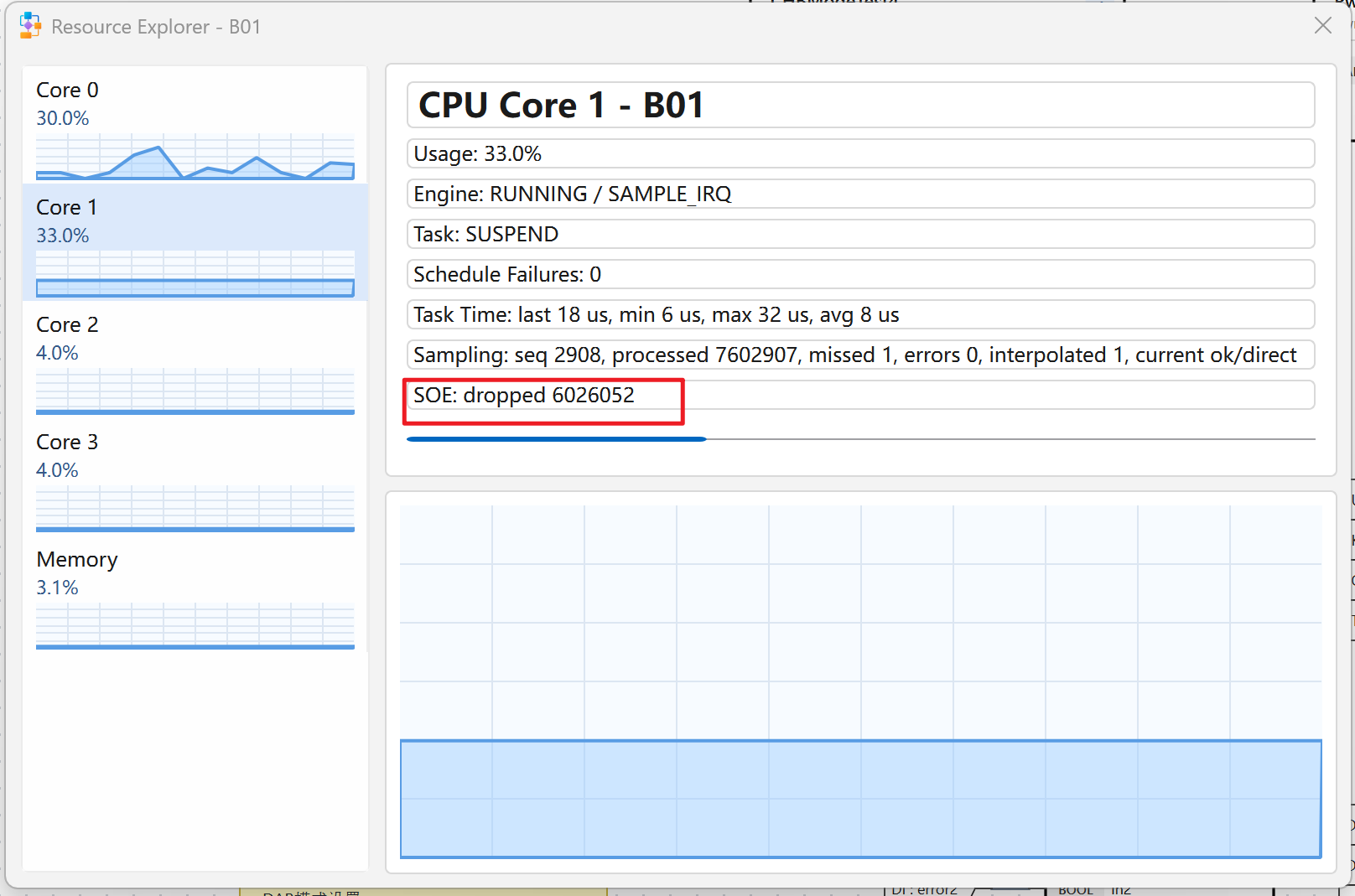
完成 SOE rpmsg 发送侧流控修改后,再次进行 DAB 功率模块实验验证。从上位机 Resource Explorer 观察结果看,Core 1 页面已经能够正常显示 SOE 背压丢弃统计,当前显示 SOE: dropped 6026052,说明引擎侧限流机制已经生效:当 SOE 变位事件超过每秒发送上限后,新产生的 SOE 通知被主动丢弃并累计计数,而不是继续无速率限制地推送给 Linux 侧。
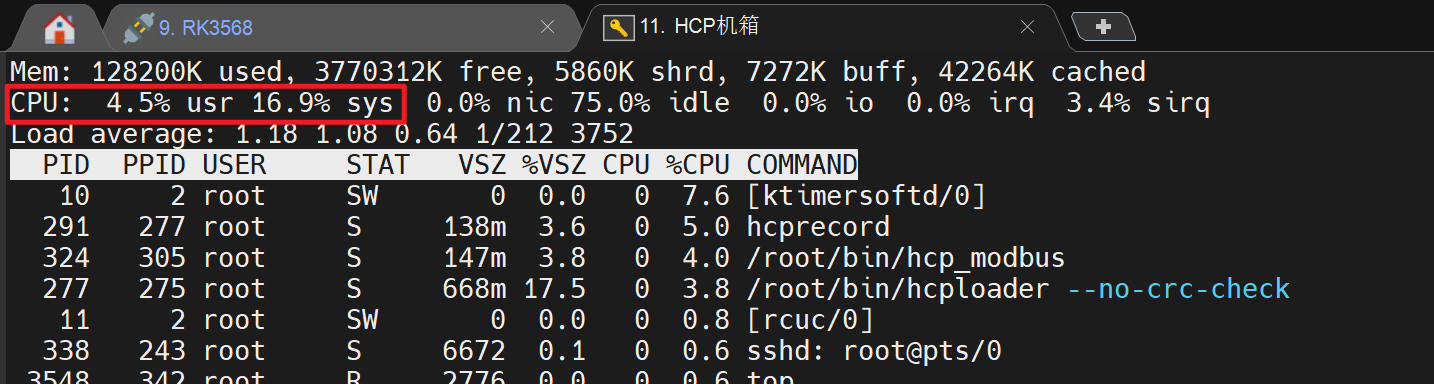
同时,通过控制器 Linux 侧 top 命令观察系统资源占用情况,系统总体 CPU 占用明显降低,CPU 空闲率保持在约 75%,内存占用也保持在较低水平,未再出现修改前 hcploader 和 mailbox 中断线程长时间高负载、内存持续增长的现象。当前 hcploader、hcp_modbus、hcprecord 等应用进程仍保持正常运行,说明 SOE 高频变位虽然仍然存在,但其对 Linux 侧 rpmsg 接收、CSV 写入和 NNG 发布链路的冲击已经被有效抑制。
从验证结果看,本次修改达到了预期目标:当现场存在 SOE 变位风暴时,引擎侧能够通过秒级窗口限速主动削峰,避免 SOE 消息持续压垮 Linux 侧处理链路;同时,丢弃事件能够通过 soeDropCount 上报到上位机界面,便于现场判断当前是否存在 SOE 高频触发问题。后续仍需进一步排查具体 SOE 注册点,避免将周期计数器、实时采样值、快速翻转状态量等高频变化变量配置为 SOE 监测对象。